用Github Pages写博客
2018-06-24 19:55
这事儿说来话长。我最近加了一个技术讨论群,今后准备每周写一些学习笔记。写的东西打算都放在github这里。顺便也想把以前发在微博文章的几篇都搬过来。所以等于是打算用github.io写博客。然而github.io只能提供静态页面服务,所以这件事做起来会比较复杂。
github.io也就是Github Pages,它能够展示repo中的静态页面,但没有服务器和数据库可以用,所以不能像真正的博客网站一样在线创建保存文章,也不能实时更新文章列表。我需要在本地将内容创建好,修改文章列表页加入新内容,然后push到线上。我也可以使用一个叫Jekyll的静态页面生成器。它在本地运行一个服务器,像Node.js一样维护整个网站。它的亮点是可以把Markdown文本转化成网页文件,并且根据文本信息安排合适的路径和url,也能自动更新文章列表。当然我还是需要自己push每次的更新。最终我没有用Jekyll,而是自己写了点javascript来实现(一部分)上述需求。主要考虑到我的文章数量不多,也不要求很多的编辑功能。不如自己造点轮子,当作一个学习的过程。
我的设想是将文本使用json格式保存为文件,前端通过url异步加载这些json,渲染到当前页面。避免每篇文章存一个静态网页,否则要修改渲染样式的话会很麻烦(Jekyll可以自动重新生成每个网页,但我就得挨个去改)。之所以存成json是为了简化渲染时的逻辑,把parse文本的逻辑放到编辑的时候,毕竟文章是一次编辑多次打开的。同时手动维护一个文章列表json文件,异步加载列表。
在文章编辑这边,相当于是做个小工具将文本标记上格式、分成段落,转化为json。支持全部Markdown语法太麻烦了,决定偷个懒使用自己定义的标记方法,只要支持少量编辑功能就好,比如斜体加粗、插入代码、插入图片等。当然图片要事先存放到固定的文件夹,通过文件名产生url在页面中打开。
目前完成了50%的样子,可以读取文章了。渲染的逻辑就是一个switch搞定,根据不同type加上不同的html tag。现在的代码长这个样子:
var jsonToHtml = function(article) {
var htmlContent =
`<h2 id="article_title">${article.title}</h2><p id="artical_date">${article.date}</p><br>`;
var paragraphs = article.text;
paragraphs.forEach(paragraph => {
var str = "";
switch (paragraph.type) {
case "head":
str = `<h3>${paragraph.data}</h3>`
break;
case "code":
str = `<pre><code>${paragraph.data}</code></pre>`
break;
case "image":
str = `<img src="${IMAGES_PATH + paragraph.data}" class="img-fluid">`
break;
case "number_list":
str = "<ol>";
paragraph.data.forEach(item => {
str = str.concat(`<li>${item}</li>`);
});
str = str.concat("</ol>");
break;
case "bullet_list":
str = "<ul>";
paragraph.data.forEach(item => {
str = str.concat(`<li>${item}</li>`);
});
str = str.concat("</ul>");
break;
case "quote":
str = `<blockquote class="blockquote"><p>${paragraph.data}</p></blockquote>`;
break;
default:
str = `<p>${paragraph.data}</p>`
break;
}
htmlContent = htmlContent.concat(str);
});
从上面代码中也能看出来json文件是什么格式。基本上就是一个段落是一个 { "type": ..., "data": ... } 这样。
编辑页面这边只是做了个样子:
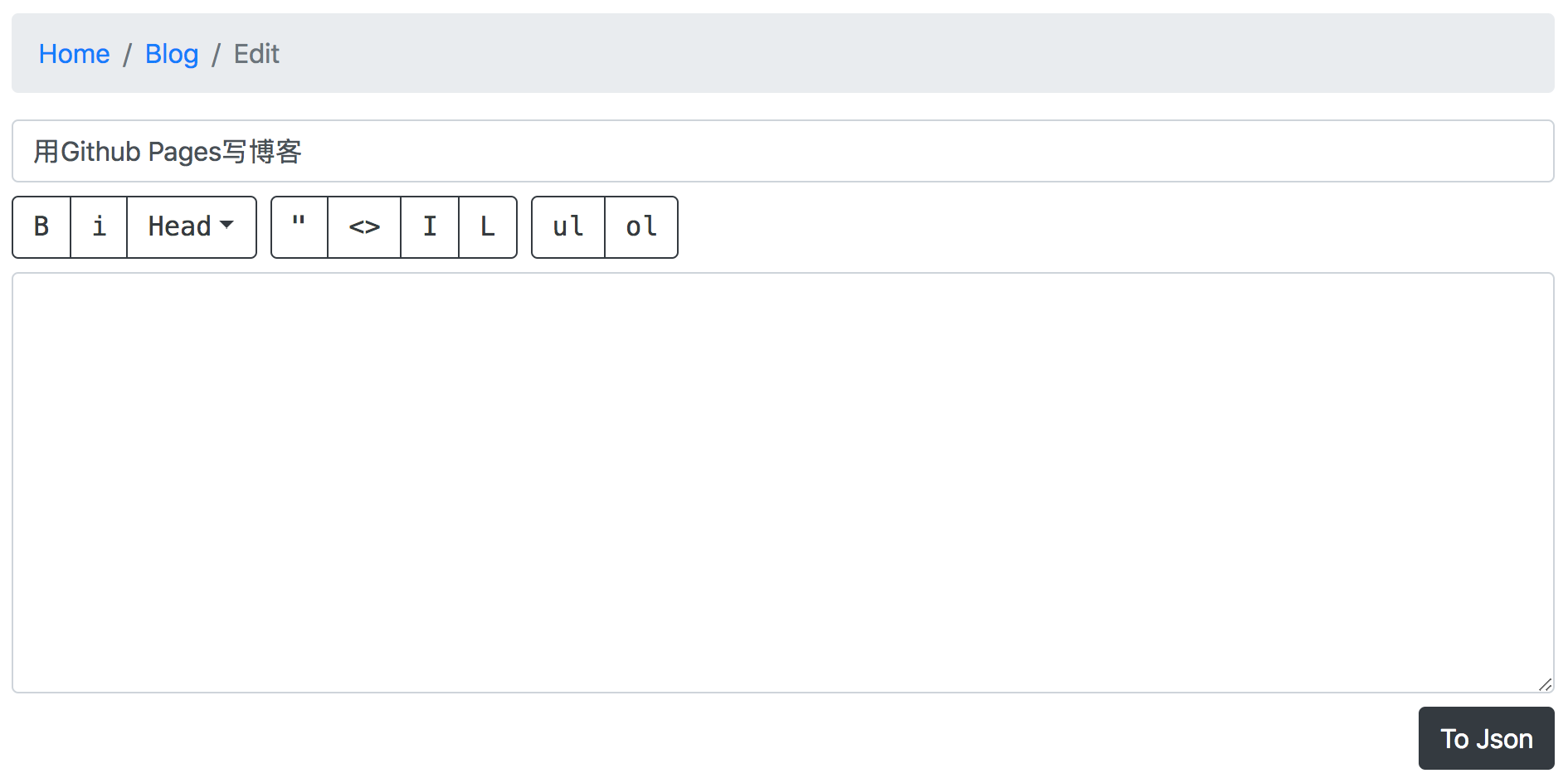
那些按钮的功能还没有写,所以现在只能手动给文本加上标记。点击“To Json”之后开始parse文本,基本上就是一个while,两个位置标记from和to。from标记当前位置,to尝试寻找一个有效段落的结束,然后将段落转化为json。然后 from = to,寻找下一个段落,直到读完全部文本。部分代码是这样的:
var parseText = function () {
var text = $('#text-input').val()
.replace(/\&/g, "&")
.replace(/\\/g, "\")
.replace(/\</g, "<")
.replace(/\>/g, ">")
.replace(/\"/g, """)
.replace(/\'/g, "'")
.concat('\n');
var paragraphs = [];
var from = 0;
var to = 0;
while (from < text.length) {
if (text.charAt(from) === '\n' || text.charAt(from) === ' ') {
from++;
} else if (text.slice(from, from + 4) === "### ") {
from += 4;
to = from;
while (to < text.length && text.charAt(to) !== '\n') {
to++;
}
paragraphs.push(parseHead(text.slice(from, to).trim()));
from = to;
} else if (text.slice(from, from + 4) === "```\n") {
from += 4;
to = text.indexOf("\n```\n", from);
if (to === -1) {
continue;
}
paragraphs.push(parseCode(text.slice(from, to)));
from = to + 4;
...
最终生成的json字串显示在页面上,拖选、复制、粘贴、保存成本地文件,修改文章列表文件,commit,push,就完成了一篇博客。。。
接下来要持续完成和完善代码。目前的主要任务,一是在文本中添加标记的功能还没开发。二是测试中发现很多edge case会导致转化失败。
其中一大类问题是字符escape,例如“<”、换行符等。除换行符以外的字符全都在一开始替换为HTML code,换行符因为涉及parse逻辑,放到晚一点的时候替换。“&”要第一个替换,因为替换其他字符的过程中会引入“&”。替换所有的“<”和“>”意味着我只能在渲染时添加html tag了,否则tag中的“<”和文本中的“<”会无法区分。测试的过程很繁琐,我最后发现最好的测试方法,是将这部分逻辑的代码本身作为测试文本。代码中集中了最多的特殊字符,而在解决一个问题的过程中所写的代码又会引入更多特殊字符,引发更多问题。这样不断迭代,直至功成。
还有一类问题是源于用户输入格式不正确,虽然目前其实只有一个用户。